- PRODUCTS
- COMPANY
- SUPPORT
- PRODUCTS
- BY TYPE
- BY MARKET
- COMPANY
Our Company
Media
Contact
- SUPPORT
BY TYPE
Compute
Networking
Custom
BY MARKET

January 15, 2025
Next Up for Custom AI Accelerators: Co-Packaged Optics
By
Michael Kanellos, Head of Influencer Relations, Marvell
Computer architects have touted the performance and efficiency gains that can be achieved by replacing copper interconnects with optical technology in servers and processors for decades1.
With AI, it’s finally happening.
Marvell earlier this month announced that it will integrate co-packaged optics (CPO) technology into custom AI accelerators to improve the bandwidth, performance and efficiency of the chips powering AI training clusters and inference servers and opening the door to higher-performing scale-up servers.
The foundation of the offering is the Marvell 6.4Tbps 3D SiPho Engine announced in December 2023 and first demonstrated at OFC in March 2024. The 3D SiPho Engine effectively combines hundreds of components—drivers, transimpedance amplifiers, modulators, etc.—into a chiplet that itself becomes part of the XPU.
With CPO, XPUs will connect directly into an optical scale-up network, transmitting data further, faster, and with less energy per bit. LightCounting estimates that shipments of CPO-enabled ports in servers and other equipment will rise from a nominal number of shipments per year today to over 18 million by 20292.
Additionally, the bandwidth provided by CPO lets system architects think big. Instead of populating data centers with conventional servers containing four or eight XPUs, clouds can shift to systems sporting hundreds or even thousands of CPO-enhanced XPUs spread over multiple racks based around novel architectures—innovative meshes, torus networks—that can slash cost, latency and power. If supercomputers became clusters of standard servers in the 2000s, AI is shifting the pendulum back and turning servers into supercomputers again.
“It enables a huge diversity of parallelism schemes that were not possible with a smaller scale-up network domain,” wrote Dylan Patel of SemiAnalysis in a December article.
Power and Performance
Why the rapid ramp? Think of CPO as a critical ingredient for ensuring artificial intelligence works in the real world. The Department of Energy recently released a report forecasting that the share of electricity consumed by data centers could nearly triple to 12% by 2028 without including bitcoin3. Communities and utilities, meanwhile, are pushing back on data center expansion plans and proposing that cloud providers pay more for grid upgrades4.
At the same time, performance requirements continue to climb. One of the next big shifts will be a movement from 100G per lane connections between systems to 200G per lane. 200G doubles bandwidth, but it roughly halves the distance signals can travel over standard copper cables. At 200G, passive copper cables can only reliably transmit data for approximately 1 meter, or not even enough to scale within a single rack.
For scale up, optical is a must.
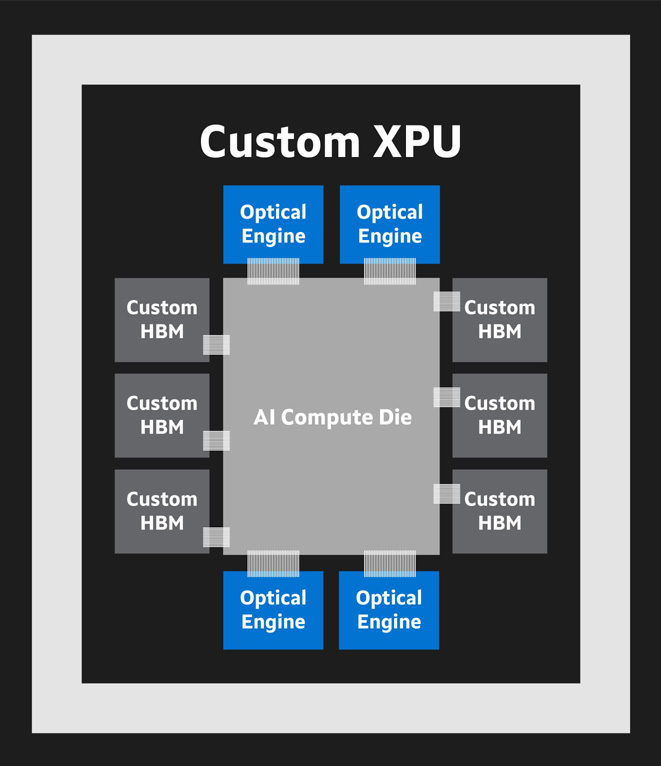
Anatomy of a custom XPU. Customizing computing cores, HBM and/or connectivity can reduce component count, signal loss, latency, and electromagnetic interference while improving performance and efficiency.
XPUs likewise are undergoing a dramatic transformation. Rather than rely on off-the-shelf GPUs, hyperscalers will increasingly deploy custom XPUs exclusively designed to meet their specific performance metrics. Marvell along with Micron, Samsung and SK hynix in December outlined a collaboration to customize the high bandwidth memory (HBM) inside XPUs. Early internal projections show custom HBM can increase the silicon available for logic by 25%, increase memory capacity by 33% and reduce memory interface power by up to 70%5.
CPO will have similar, positive impacts on overall accelerator design. The 6.4Tbps 3D SiPho Engine will be capable of delivering far greater bandwidth at enhanced reach compared to traditional copper interconnects, which translates to fewer components and volumetric space to deliver the same level of performance. Another advantage: the copper interconnect leading out of the accelerator to the scale-up compute fabric is incredibly short- it stays within the chip package. Reducing the length provides headroom for greater bandwidth and more reliable signals.
Put another way, CPO is effectively allowing designers to make more versatile, efficient chips so they can create far larger AI systems.
------
1. HPC 2021. https://www.hpcwire.com/2002/03/08/intel-to-make-optical-chips-for-others/
2. LightCounting, AOC, DACs, Linear Drive Optics and Co-Packaged Optics December 2024.
3. US DOE December 2024.
4. Columbus Dispatch. May 2024.
5. Marvell estimates.
####
Marvell and the M logo are trademarks of Marvell or its affiliates. Please visit www.marvell.com for a complete list of Marvell trademarks. Other names and brands may be claimed as the property of others.
This blog contains forward-looking statements within the meaning of the federal securities laws that involve risks and uncertainties. Forward-looking statements include, without limitation, any statement that may predict, forecast, indicate or imply future events or achievements. Actual events or results may differ materially from those contemplated in this blog. Forward-looking statements are only predictions and are subject to risks, uncertainties and assumptions that are difficult to predict, including those described in the “Risk Factors” section of our Annual Reports on Form 10-K, Quarterly Reports on Form 10-Q and other documents filed by us from time to time with the SEC. Forward-looking statements speak only as of the date they are made. Readers are cautioned not to put undue reliance on forward-looking statements, and no person assumes any obligation to update or revise any such forward-looking statements, whether as a result of new information, future events or otherwise.
Tags: custom computing, ASIC, AI accelerator processing units, AI, Optical Connectivity, server connectivity, Silicon Photonics Light Engines
Recent Posts
Archives
Categories
- 5G (12)
- AI (30)
- Automotive (26)
- Cloud (16)
- Coherent DSP (10)
- Company News (103)
- Custom Silicon Solutions (7)
- Data Center (55)
- Data Processing Units (22)
- Enterprise (25)
- ESG (6)
- Ethernet Adapters and Controllers (12)
- Ethernet PHYs (4)
- Ethernet Switching (41)
- Fibre Channel (10)
- Marvell Government Solutions (2)
- Networking (36)
- Optical Modules (15)
- Security (6)
- Server Connectivity (26)
- SSD Controllers (6)
- Storage (22)
- Storage Accelerators (2)
- What Makes Marvell (40)

Copyright © 2025 Marvell, All rights reserved.
- Terms of Use
- Privacy Policy
- Contact