
The Marvell custom HBM compute architecture enables the design of high-bandwidth memory (HBM) systems tailored specifically for AI accelerators (XPUs). By integrating advanced 2.5D packaging technology and custom interfaces, this architecture overcomes the limitations of standard interface-based designs, enabling higher compute and memory density with improved power efficiency.
Key features:
Will Chu, SVP and GM of Custom Compute and Storage at Marvell, In Dong Kim, VP of Product Planning and Business Enabling at Samsung Semiconductor and Sunny Kang, VP of DRAM Technology at SK hynix discuss the how HBM will become the mainstream solution for hyperscalers on the Six Five.
Marvell custom HBM compute architecture is the result of strategic partnerships with industry-leading memory manufacturers to redefine the future of AI acceleration:
"Increased memory capacity and bandwidth will help cloud operators efficiently scale their infrastructure for the AI era."
Raj Narasimhan, SVP and GM Compute and Networking Business Unit, Micron
"Collaborating with Marvell allows us to help customers produce optimized solutions for their workloads and infrastructure."
Sunny Kang, VP of DRAM Technology, SK hynix
"Optimizing HBM for specific XPUs and software environments will greatly improve the performance of cloud operators’ infrastructure."
Harry Yoon, EVP, Samsung Electronics
The diagram illustrates the evolution of HBM integration within XPUs, showcasing Marvell innovations that optimize the I/O interface to save up to 25% silicon real estate while boosting compute and memory capacity. The simplified I/O architecture enables efficient memory access, lower power consumption, and improved scalability for AI workloads. It emphasizes the collaboration between compute logic, HBM stacks, and advanced packaging technologies to create a holistic, efficient design.
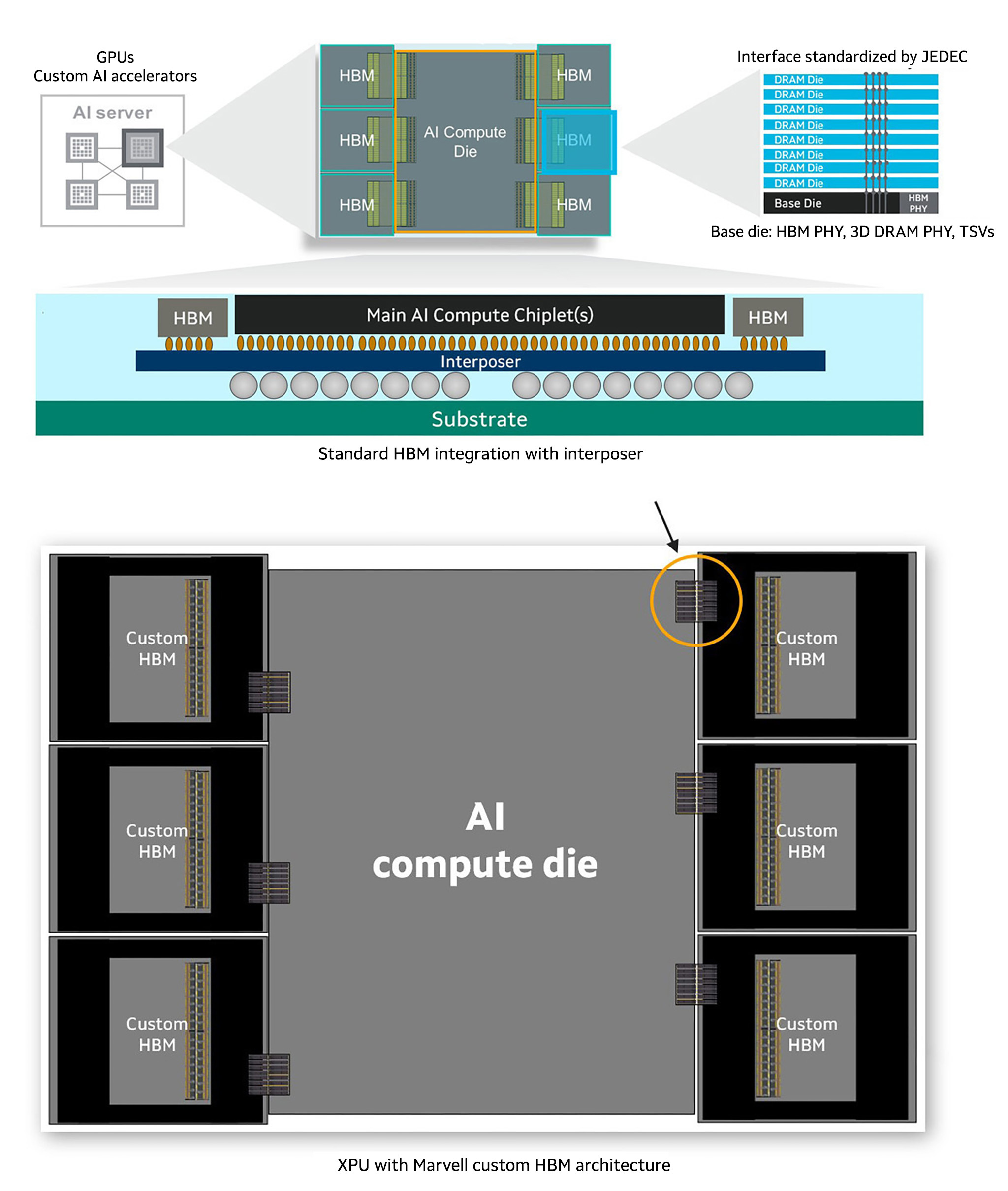
Today’s XPUs can contain four or more vertically integrated stacks of HBM with a cumulative capacity of 192GB that are connected to processing units through thousands of individual channels.
Next-generation XPUs will demand even more capacity and higher transfer rates, creating challenges in thermal management, power delivery, cost and interface performance.
The Marvell custom HBM compute architecture provides hyperscalers with a roadmap to better performance and lower TCO by dramatically reducing the size and power consumption of HBM interfaces and controllers. Benefits include:


The future of computing is custom. With Moore’s Law nearing its limits, performance and efficiency gains will increasingly be achieved through breakthrough ideas in core design, materials, packaging, interfaces, and other aspects of semiconductor design. By 2028, it is estimated that 25% of AI processors will be based around custom designs and technologies.
These custom processors will power systems designed around a unique combination of devices that, in concert, will deliver unprecedented throughput, efficiency, and TCO. Every cloud will be unique because the underlying silicon will be unique.
Marvell is at the forefront of the custom revolution. We have developed a portfolio of technologies and services to help an expanding spectrum of customers create infrastructure that will enable them to achieve their goals for growth, sustainability, performance and customer service.

Marvell custom devices are designed to meet the high-speed, high-performance silicon needs of AI and cloud infrastructure, 5G and enterprise networks, and automotive applications. With a growing IP portfolio at advanced nodes, including 2nm, Marvell delivers optimized solutions in compute, networking, security, storage, and high-speed SerDes, ensuring faster time-to-market and maximum performance, power, and area efficiency. Over the past 25 years, Marvell has delivered over 2,000 custom ASICs, driving innovation for future-ready solutions.
We believe better partnerships help to build better technologies. Let’s connect and see what we can design together!
We will be in touch with you soon!
